Trapetum
Benchmarks
One machine (RTX 4090, RunPod), one model (NousResearch/Llama-2-7B-hf), every number measured and reproducible. No invented figures: if a metric is absent from the sources, it is absent here too.
End-to-end Pareto: speed, memory, accuracy, energy
Batch-1 decode, all decode metrics measured over a 512-token generation (iso-context). Wikitext-2 PPL over 30 000 tokens, context 2048 (generation-independent). Energy via pynvml power.draw. The Rust runtime row uses the same 4-bit weights as the Python row, with no Python at runtime.
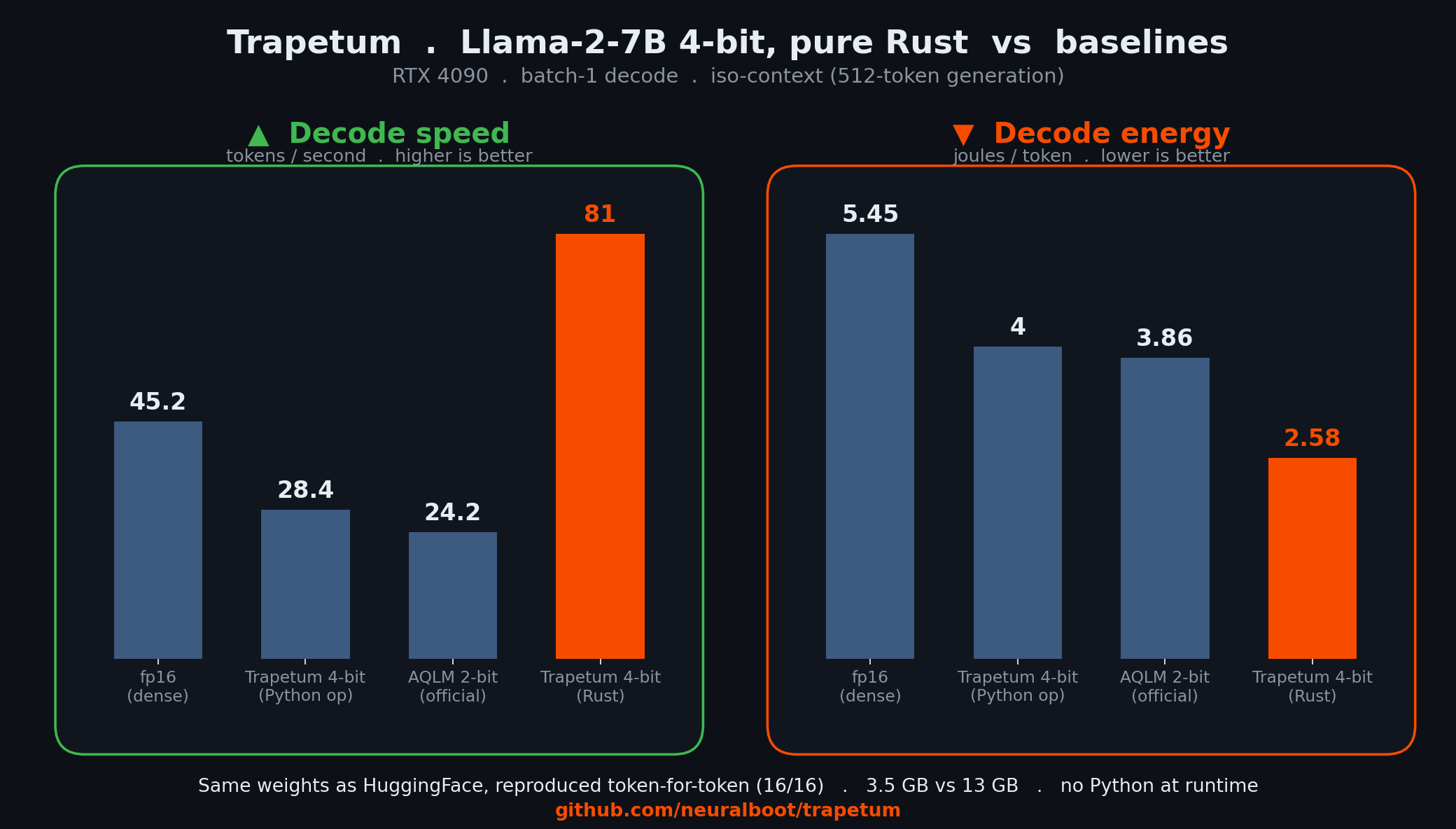
| Method | Bits | VRAM (GB) | Wikitext PPL | Decode tok/s | J/token | gCO2/1k FR | gCO2/1k US |
|---|---|---|---|---|---|---|---|
| fp16 (cuBLAS baseline) | 16.0 | 13.48 | 5.28 | 45.2 | 5.45 | 0.076 | 0.61 |
| Trapetum 4-bit, Python op ours | 4.05 | 3.81 | 5.92 | 28.4 | 4.00 | 0.056 | 0.44 |
| aqlm-2bit (official kernel) | 2.0 | 2.15 | 7.01 | 24.2 | 3.86 | 0.054 | 0.43 |
| Trapetum 4-bit, Rust runtime ours | 4.05 | 4.73* | 5.92 | 81 | 2.58 | 0.036 | 0.29 |
* 4.73 GB measured peak (3.5 GB weights + KV cache + activations). The short-context Rust throughput reaches 135 tok/s.
gCO2/1k-tok is a derived projection, not a measurement: gCO2 = J/token x grid intensity at France-like (~50 gCO2/kWh) or US-like (~400 gCO2/kWh) intensity. RunPod's actual grid mix is unknown. J/token is what is measured.
Reading the table honestly
- Energy is the headline. The Rust runtime runs the same 4-bit weights at 2.58 J/token, 2.1x less than fp16 (5.45) and ~1.5x less than the Python-wrapped kernel (4.00), iso-context.
- Speed gap, Python vs Rust. The 4-bit weights via a Python custom op decode at 28.4 tok/s, slower than fp16 (45.2). The bottleneck is Python per-op dispatch (224 calls/token), not the kernel. The same weights in Rust reach 81 tok/s (1.8x fp16 at this context). The Python-to-Rust gap is the overhead cost made visible.
- Accuracy/memory curve. fp16 (PPL 5.28, 13.5 GB) to Trapetum 4-bit (PPL 5.92, 3.8 GB) to AQLM 2-bit (PPL 7.01, 2.1 GB). Nothing beats dense on accuracy.
- Mean GPU power (Rust row): 209 W, measured via pynvml over the 512-token window.
Does it run on your GPU?
Trapetum is CUDA, so it runs on any modern NVIDIA GPU. You recompile the kernel for your architecture with one -arch flag, or ship a multi-arch build that covers them all in a single binary. The 4-bit memory saving is universal; only the speedup depends on the card.
| Your GPU | Arch | Memory win | Decode speed |
|---|---|---|---|
| RTX 30 / 40 series (3060, 3090, 4070, 4090, ...) | sm_86 / sm_89 | ~3.5x less | largest gain, up to 2.2x |
| A100 / A40 / L40 | sm_80 / sm_86 / sm_89 | ~3.5x less | strong, 2.3x on A40 |
| H100 / H200 | sm_90 | ~3.5x less | parity (fp16 already near roofline) |
| Turing and older (GTX 16, RTX 20, V100) | sm_70 / sm_75 | ~3.5x less | untested, rebuild needed |
| AMD, Apple Silicon, CPU | - | - | not supported (CUDA only) |
The point: the memory win (a 7B in ~3.5 GB, so it fits an 8 GB card) holds on every NVIDIA GPU. The speed win is largest exactly where most people run, on bandwidth-limited consumer cards. Validated on Ampere, Ada and Hopper (sm_80 to sm_90); pre-Ampere is untested.
Kernel microbenchmarks
Synthetic matrices (IC = OC = 4096, fp16 activations/output, batch M = 1), fixed seed mt19937(0). Timings use CUDA events over 50-500 iterations after warmup. All variants verified numerically against cuBLAS on the same random data.
Decode GEMV (A40, sm_86, CUDA 11.8)
Decode is memory-bound: reading fewer weight bytes directly buys latency. The lever is bits per index.
| Kernel | Scheme | Latency (ms) | vs cuBLAS | Max rel. err |
|---|---|---|---|---|
| cuBLAS fp16 dense (baseline) | dense fp16 | 0.0612 | 1.00x | - |
| gemv_codebook.cu | uint8, K = 256 | 0.0562 | 1.09x | 2.9e-5 |
| gemv_codebook.cu | uint8, K = 64 | 0.0389 | 1.57x | 2.4e-5 |
| gemv_codebook_4bit.cu fastest | 4-bit, K = 16 | 0.0261 | 2.34x | 2.6e-5 |
Cross-GPU decode (4-bit, K = 16, 4096x4096, batch 1)
The bandwidth law: the more bandwidth-limited the GPU, the larger the speedup from reading 1/4 the weight bytes. On a bandwidth-rich H100 the fp16 GEMV is already near roofline, so the kernel only ties.
| GPU | Bandwidth class | Speedup vs cuBLAS fp16 | Rel. err |
|---|---|---|---|
| RTX 4090 (sm_89) | ~1.0 TB/s | 2.20x | 3e-4 |
| A40 (sm_86) | ~0.7 TB/s | 2.34x | 3e-4 |
| H100 PCIe (sm_90) | ~3.3 TB/s | 0.99x (parity) | 3e-4 |
Per-layer PyTorch op speedup vs torch dense fp16 (RTX 4090)
Speedup of the custom codebook_gemv op versus torch.mv (the batch-1 path a real fp16 Linear runs), by layer shape. Tiny matrices are overhead-bound and lose; the large MLP layers that dominate LLM parameter count win by 3.7x.
| Layer (IC x OC) | Speedup vs torch dense fp16 |
|---|---|
| 3072 x 768 (small) | 0.58x (loses, overhead-bound) |
| 4096 x 4096 | 2.10x |
| 11008 x 4096 (MLP down) | 3.70x |
| 4096 x 11008 (MLP up) | 3.77x |
Apply the kernel selectively to large layers. Reproduce with python kernels/shapes_test.py.
Dequantization bandwidth (A40)
| Kernel | Effective bandwidth |
|---|---|
| naive (redundant shared-memory staging) | 31.8 GB/s |
| dequant_l2 (L2-cached gather) | 213 GB/s (6.7x) |
Additive vector-quantization GEMV (AQLM-style, 2-bit)
A fused decode kernel for additive (AQLM-style) codebooks: builds a per-group LUT in shared memory, then reads only the codes. At 2 bits (M=2, K=256, D=8) that is 4.2 MB of codes versus 33.6 MB of fp16 weight. Measured vs live cuBLAS fp16 GEMV at 4096x4096, rel. err 2.3e-4.
| GPU | 2-bit (M=2) vs cuBLAS | 4-bit (M=4) vs cuBLAS |
|---|---|---|
| RTX 4090 (~1.0 TB/s) | 1.71x | - |
| A40 (~0.7 TB/s) | 4.30x | 2.39x |
The key optimization for v3: vectorized 32-bit code reads (four 8-bit codes per thread), which lifted the A40 from 2.35x to 4.30x. The kernel decodes real AQLM weights (Llama-2-7b-AQLM-2Bit-2x8-hf format maps one-to-one onto this kernel).
Model-level results: Llama-2-7B end-to-end (RTX 4090)
All 224 projection layers quantized to Trapetum 4-bit (K = 16, per-column k-means). Evaluated end to end on an RTX 4090.
| Integration path | Decode tok/s | VRAM (GB) | vs fp16 |
|---|---|---|---|
| fp16 baseline (cuBLAS) | 61.6 | 13.58 | 1.00x |
| naive per-layer custom-op swap | 44 (est.) | 4.73 | 0.73x |
| cast-free eager (no per-op float32 cast) | ~52 (est.) | 4.73 | ~0.85x |
| CUDA-graphed decode loop (clean integration) ships | 123.4 | 4.73 | 2.0x |
The progression 0.73x (naive) to 0.85x (cast-free) to 2.0x (CUDA-graphed) shows that the kernel win is real: it takes proper CUDA-graph integration to see it end to end. Memory drops 2.9x (13.56 GB to 4.63 GB).
Llama-2-13B on A40 (bandwidth law at scale)
| Model/method | Decode tok/s | VRAM (GB) | Speedup | Memory ratio |
|---|---|---|---|---|
| Llama-2-13B fp16 (A40) | 20.0 | 26.17 | 1.00x | - |
| Llama-2-13B Trapetum 4-bit (A40) | 49.0 | 8.50 | 2.46x | 3.08x less |
Accuracy: 4-bit accuracy attempts on Llama-2-7B
| Scheme (4-bit, Llama-2 7B) | Wikitext-2 PPL |
|---|---|
| fp16 baseline | 5.83 |
| Trapetum scalar (this work) | 6.34 |
| + activation-aware calibration | 6.17 |
| + per-channel scale search | 6.18 |
| + full AWQ pipeline (scale + clip) | 6.21 |
| + incoherence processing (QuIP# lever) | 6.29 |
| beam-search + least-squares additive VQ (this work) | 6.13 |
The calibration and VQ attempts to close the accuracy gap are documented negative results. The best accuracy at 4-bit is the trained additive VQ (6.13 PPL), which also decodes at 2.39x (A40). The value of this scheme is memory and kernel speed, not accuracy.
Multi-method comparison (H100, from the paper)
A fair single-harness benchmark of fp16, AWQ, and AQLM on Llama-2 7B and 70B. Full wikitext-2 PPL, HuggingFace forward path, greedy, batch 1, seed 0. The fp16 7B PPL of 5.47 and AWQ 70B PPL of 3.41 match published values, which validates the harness.
| Model | Method | Decode (tok/s) | VRAM (GB) | Wikitext-2 PPL |
|---|---|---|---|---|
| Llama-2 7B | fp16 | 43.7 | 15.3 | 5.47 |
| Llama-2 7B | AWQ 4-bit | 26.8 | 5.7 | 5.60 |
| Llama-2 7B | AQLM 2-bit | 25.0 | 4.2 | 6.34 |
| Llama-2 70B | fp16 | ~138 GB, does not fit on one 80 GB GPU | ||
| Llama-2 70B | AWQ 4-bit | 9.1 | 38.4 | 3.41 |
| Llama-2 70B | AQLM 2-bit | 9.2 | 20.7 | 4.06 |
At 7B on H100, every quantized method decodes slower than fp16: bandwidth is high enough that fp16 is already fast and the dequant overhead dominates. At 70B, the story flips: AQLM 2-bit fits in 20.7 GB on a single 24 GB consumer GPU, and at PPL 4.06 it is markedly more accurate than fp16 7B (PPL 5.47) at comparable memory.
Methodology and hardware
Hardware
RTX 4090 (RunPod), CUDA 11.8/12.x (as reported per run), sm_89 for 40-series, sm_86 for A40, sm_90 for H100 PCIe. All kernel microbenchmarks at matrix shape IC = OC = 4096.
Randomness and reproducibility
All kernel randomness is generated by std::mt19937(0) (fixed seed 0). Timings use cudaEvent over 50-500 iterations after warmup. Every kernel is checked for numerical correctness against cuBLAS on the same random data; the maximum relative error is reported.
Energy measurement
pynvml power.draw sampled over the full 512-token generation window. J/token = (mean power W) x (time per token s). The Rust runtime row: 209 W mean, 2.58 J/token. gCO2/1k-tok is derived from J/token x grid intensity (not measured).
Wikitext-2 PPL
Full 30 000 token evaluation, context window 2048, stride 512. Generation-independent (does not depend on decode length). HuggingFace forward path, greedy, batch 1, seed 0.
Reproducing the numbers
All code, raw JSON results, and figures are public. The full table regenerates itself on your GPU:
# one kernel (adjust -arch: sm_80/A100, sm_86/A40, sm_89/RTX40, sm_90/H100) nvcc -O3 -arch=sm_90 kernels/gemv_codebook_4bit.cu -o gemv4 && ./gemv4 # full kernel reference table (writes results.json + results.md) python kernels/benchmark.py --arch sm_90 # end-to-end Pareto (Python rows) python bench/pareto.py --gen 512 # Rust runtime row (requires the .cbk quantized model) generate <model.cbk> ... 512 # per-layer PyTorch op shapes python kernels/shapes_test.py # additive VQ kernel (2-bit, K=16, A40) nvcc -O3 -arch=sm_86 -DGT=16 kernels/avq_gemv3.cu -lcublas -o avq3 && ./avq3
Honest limits
- Accuracy ceiling. The Trapetum scalar does not beat fp16 on accuracy and never will. It is behind vector and trellis methods (AQLM, QuIP#, QTIP) at low bits. Three calibration and VQ attempts to close the gap are documented negative results. The value of this scheme is memory and kernel speed.
- Bandwidth law. The kernel speedup is largest on bandwidth-limited GPUs (RTX 4090 x2.20, A40 x2.34). On a bandwidth-rich H100, fp16 GEMV is already near roofline and the kernel only ties (x0.99). The win lives on the hardware most users actually run.
- Batch-1 decode only. Batched throughput needs a GEMM path. The Tensor-Core prefill experiments (prof10/11.cu) reached ~0.21x cuBLAS. Batched throughput is an open problem, not a quick reuse of the decode kernel.
- Synthetic data for microbenchmarks. Codebooks and indices are random (mt19937(0)). Real weight and index distributions may differ.
- Single shape. Kernel microbenchmarks at IC = OC = 4096. Numbers will differ at other shapes; re-run benchmark.py.
- No comparison against kernel peers. The only baseline is cuBLAS fp16. A fair speed comparison would benchmark against Marlin, FLUTE, VQ-LLM, and the QuIP#/QTIP/AQLM kernels at matched accuracy on a real model. That comparison is not done here.
- Prefill stays at ~0.21x cuBLAS. Trapetum buys memory in the compute-bound regime, not speed. Closing the remaining gap requires production-Marlin engineering (ldmatrix + shared-memory swizzling).